“An ounce of performance is worth pounds of promises”
© Mae West
Speed for the sake of Speed
Benchmarks, performance, speed comparisons, metrics, apples to apples, apples to nuclear weapons.. We, software developers “for real”, know that all that is irrelevant. What relevant is a clear problem definition, flexible data model, simple tool/way to solve it, a feeling of accomplishment, approved billing papers, moving along closer to the stars..
All is true, premature optimization is the root of all evil, readability over pointer arithmetic, performance does not really matter,… until it does. Until a problem definition itself is numbers over time i.e. ..ions per second.
It is not only HFT that defines capabilities of trading companies in their ability to cope with speed of light and picoseconds. Having big data and real time online processing coming out of basements and garages and finally hitting the brains of suits who suddenly “get it” and have money ready for it, makes a new wave of “performance problems” that are “just that”: little bit of business behind the problem, and mostly raw things per second.
Never Trust Sheep
© Ryan Stiles
Interesting thing about choosing the right database for a problem today is the fact that there are just so many available, and many scream that they can do everything for you, from storing data to taking your shirts to dry cleaning on Wednesdays if you buy a dozen of their enterprise licensees. One thing I learned is “to be quick and efficient we have to mute screamers and assholes”, so some fruit and fragile NoSQL boys and Oracle are out.
Datomic is kind of a new kid on a block. Although the development started about 3 years ago, and it was done by Relevance and Rich Hickey, so it is definitely ready for an enterprise ride. To put in into perspective: if MongoDB was ready for Foursquare as soon as MongoDb learned to “async fsync”, then given the creds, Datomic is ready for NASA.
Speed and Time
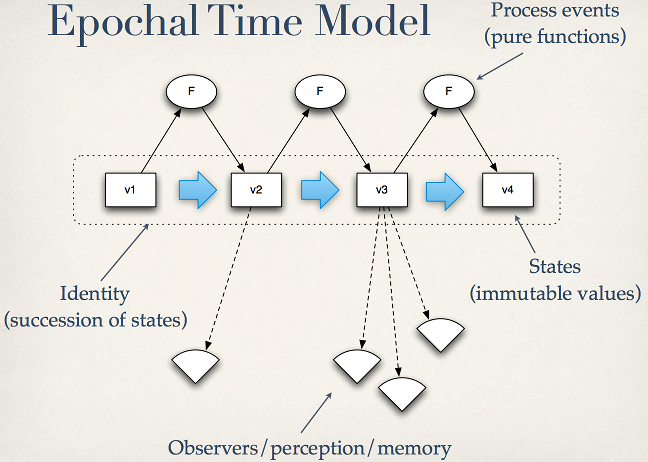
While usually all Datomic discussions involve “time” and rely on Cojure’s core principles of “Epochal Time Model”, this novel introduces another main character: “Speed”.
Datomic processes write transactions by sending them to a transactor via queue, which is currently HornetQ. Hornet claims to be able to do millions a second with SpecJms2007.
Before transaction is off to a tx queue it needs to be created though. It usually consist out of one or more queries. The documented, and recommended, way to create a query is a Datomic’s implementation of Datalog. It is a nice composable way to talk to the data.
While writes are great, and HornetQ looks quite promising, the fact that Datomic is ACID, and all the writes are coordinated by a transactor, Datomic is not (at least not yet) a system that would be a good fit for things like clickstream data. It does not mean writes are slow, it just means that it is not for 1% of problems that need “clickstream” like writes.
Reads are another story, one of the kickers in Datomic is having access to the database as a value. While “as a value” part sounds like a foreign term for a database, it provides crazy benefits: immutability, time, …, and among all others it provides a database value inside the application server that runs queries on it. A closest analogy is a git repository where you talk to the git repo locally, hence “locality of references”, hence caching, hence fast reads.
Peeking into The Universe
It is always good to start from the beginning, so why not start directly from the source: The Universe. Humans naively separated The Universe into galaxies, where a single galaxy has many planets. So here is our data model, many galaxies and many planets:
(def schema [
{:db/id #db/id[:db.part/db]
:db/ident :universe/planet
:db/valueType :db.type/string
:db/cardinality :db.cardinality/many
:db/index true
:db.install/_attribute :db.part/db}
{:db/id #db/id[:db.part/db]
:db/ident :universe/galaxy
:db/valueType :db.type/string
:db/cardinality :db.cardinality/many
:db/index true
:db.install/_attribute :db.part/db} ]) |
(def schema [
{:db/id #db/id[:db.part/db]
:db/ident :universe/planet
:db/valueType :db.type/string
:db/cardinality :db.cardinality/many
:db/index true
:db.install/_attribute :db.part/db}
{:db/id #db/id[:db.part/db]
:db/ident :universe/galaxy
:db/valueType :db.type/string
:db/cardinality :db.cardinality/many
:db/index true
:db.install/_attribute :db.part/db} ])
Here is the data we are going to be looking for:
(def data [
{:db/id #db/id[:db.part/user]
:universe/galaxy "Pegasus"
:universe/planet "M7G_677"} ]) |
(def data [
{:db/id #db/id[:db.part/user]
:universe/galaxy "Pegasus"
:universe/planet "M7G_677"} ])
And here is a Datalogy way to look for planets in Pegasus galaxy:
(d/q '[:find ?planet :in $ ?galaxy
:where [?e :universe/planet ?planet]
[?e :universe/galaxy ?galaxy]] (db *conn*) "Pegasus") |
(d/q '[:find ?planet :in $ ?galaxy
:where [?e :universe/planet ?planet]
[?e :universe/galaxy ?galaxy]] (db *conn*) "Pegasus")
Which returns an expected planet: #{[“M7G_677”]}
Secret of a Clause
Now let’s bench it. I am going to use criterium:
(bench
(d/q '[:find ?planet :in $ ?galaxy
:where [?e :universe/planet ?planet]
[?e :universe/galaxy ?galaxy]] (db *conn*) "Pegasus")) |
(bench
(d/q '[:find ?planet :in $ ?galaxy
:where [?e :universe/planet ?planet]
[?e :universe/galaxy ?galaxy]] (db *conn*) "Pegasus"))
Evaluation count : 384000 in 60 samples of 6400 calls.
Execution time mean : 169.482941 µs |
Evaluation count : 384000 in 60 samples of 6400 calls.
Execution time mean : 169.482941 µs
170µs for a lookup.. not too shabby, but not blazing either.. Can we do better? Yes.
The way Datalog is implemented in Datomic, it takes less time, and needs to do less, if most specific query clauses are specified first. In the example above “[?e :universe/galaxy ?galaxy]” is the most specific, since the “?galaxy” is provided as “Pegasus”. Let’s use this knowledge and bench it again:
(bench
(d/q '[:find ?planet :in $ ?galaxy
:where [?e :universe/galaxy ?galaxy]
[?e :universe/planet ?planet]] (db *conn*) "Pegasus")) |
(bench
(d/q '[:find ?planet :in $ ?galaxy
:where [?e :universe/galaxy ?galaxy]
[?e :universe/planet ?planet]] (db *conn*) "Pegasus"))
Evaluation count : 384000 in 60 samples of 6400 calls.
Execution time mean : 158.893114 µs |
Evaluation count : 384000 in 60 samples of 6400 calls.
Execution time mean : 158.893114 µs
The “clause trick” shaved off 10µs, which is pretty good. But can we do better? We can.
The Art of Low Level
Since I was a kid, I knew that Basic is great, but it is for kids, and Assembly is the real deal. While Datalog is not Basic, and it is really powerful and good for 95% of cases, there are limitations with how fast you can go. Again, most of the time, a 200µs lookup is more than enough, but sometimes it is not. At times like these we turn to Datomic Assembly: we turn directly to indices.
While in the universe of other DB engines and languages doing something low level requires reading 3 books and then paying a consultant to do it, in Clojuretomic land it is a simple function that is called datoms:
datoms
function
Usage: (datoms db index & components)
Raw access to the index data, by index. The index must be supplied,
and, optionally, one or more leading components of the index can be
supplied to narrow the result.
:eavt and :aevt indexes will contain all datoms
:avet contains datoms for attributes where :db/index = true.
:vaet contains datoms for attributes of :db.type/ref
:vaet is the reverse index |
datoms
function
Usage: (datoms db index & components)
Raw access to the index data, by index. The index must be supplied,
and, optionally, one or more leading components of the index can be
supplied to narrow the result.
:eavt and :aevt indexes will contain all datoms
:avet contains datoms for attributes where :db/index = true.
:vaet contains datoms for attributes of :db.type/ref
:vaet is the reverse index
And it is not just simple, it also works. Let’s cook a generic lookup function that would lookup an attribute of an entity by another attribute of that same entity:
(defn lookup [?a _ a v]
(let [d (db *conn*)]
(map #(map :v (d/datoms d :eavt (:e %) ?a))
(d/datoms d :avet a v)))) |
(defn lookup [?a _ a v]
(let [d (db *conn*)]
(map #(map :v (d/datoms d :eavt (:e %) ?a))
(d/datoms d :avet a v))))
A couple of things:
First we look for an entity with an attribute “a” that has a value “v”. For that we’re peeking into the AVET index. In other words, we know “A” and “V” from “AVET”, we are looking for an “E”.
Then we map over all matches and get the values of an attribute in question: “?a”. This time we’d do that by peeking into “EAVT” index. In other words, we are looking for a value “V”, by “E” and “A” in “EAVT”.
Note that idiomatically, or should I say datomically, we should pass a database value into this “lookup” function, since it would enable lookups across time, and not just “the latest”.
Let’s bench it already:
(bench
(doall
(lookup :universe/planet :by :universe/galaxy "Pegasus"))) |
(bench
(doall
(lookup :universe/planet :by :universe/galaxy "Pegasus")))
Evaluation count : 11366580 in 60 samples of 189443 calls.
Execution time mean : 5.848209 µs |
Evaluation count : 11366580 in 60 samples of 189443 calls.
Execution time mean : 5.848209 µs
Yep, from 170µs to 6µs, not bad of a jump.
Theory of Relativity
All performance numbers are of course relative. Relative to the data, to the hardware, to the problem and other sequence of events. The above is done on “Mac Book Pro 2.8 GHz, 8GB, i7 2 cores” with a 64 bit build of JDK 1.7.0_21 and “datomic-free 0.8.3862”. Having Clojure love for concurrency I would expect Datomic performance (i.e. those 6µs) to improve even further on the real multicore server.
Another thing to note, above results are from a single Datomic instance. Since Datomic is easily horizontally scalable, by partitioning reads and having them go out against “many Datomics” (I am not using a “cluster” term here, since the database is a value and it is/can be collocated with readers) the performance will improve even further.
While most of the time I buy arguments on how useless benchmarks are, sometimes they really do help. And believe it or not, my journey from Datalog to Datomic indicies, with a strictly performance agenda, made it possible to apply Datomic to the real big money problem, beyond hello worlds, git gists and prototypes that die after the “initial commit”.